注意:この状況は日々変化するようなので、
この記事の日付や、カーネルバージョン、
VMwareTools のビルドバージョンに注意してください。
host: Windows7
VMwarePlayer6
guest: Ubuntu Server 14.04.2 64bit (GNU/Linux 3.16.0-30)
共有フォルダを行うためには、
VMwareTools をインストールする必要があり、
そのために gcc などが必要なので、
ゲスト OS インストール直後に以下を実施。
$ sudo apt-get install builed-essential
その後、VMwareTools をインストールする。
以下のページが一番細かくてよかった(ゲストOS違うけど大丈夫)。
CentOS6.2にVMware Toolsをインストールする | mawatari.jp
http://mawatari.jp/archives/centos-6-2-vmware-tools-install-log
普通であれば、これで終了、のはずなのだけど。
状況
そうだ、ゲストOS の Ubuntu Server のバージョンが 12 で古いから、
バージョンアップしてみよう!と思ったのがはじまり。
カーネルも全部バージョンアップしてみたら、
ゲスト OS が起動しなくなった。
その後、新規に VM を作ってみたが、
どれもゲストとの共有フォルダで失敗する。
・VMwarePlayer7 + Ubuntu Server14
・VMwarePlayer7 + Ubuntu Server12
・VMwarePlayer5 + Ubuntu Server12 ←数年前に成功した組み合わせなのに!
・VMwarePlayer6 + Ubuntu Server14
/mnt/hgfs 以下に何もない。
/etc/mtab, /etc/fstab に .host:/ に相当する記述がないので、
以下を実行するが、マウントされない。
$ sudo mount -t vmhgfs .host:/ /mnt/hgfs
/mnt/hgfs 以下も何も表示されない。
mtab や fstab に追記してみたが、変化なし。
VMwareTools がダメなら oss だぜ!と思ったけどやっぱりダメだった。
$ sudo apt-get install open-vm-tools
よく見ると、VMwareTools のインストール中に、エラーが出ていた。
エラーの詳細は以下のページとまったく同じ。
Linux 3.x の仮想マシンから VMware Fusion の共有フォルダが見えない - いままでのこと
HGFS fails to compile on kernel 3.16.2 ・ Issue #11 ・ rasa/vmware-tools-patches ・ GitHub
検索でお越しになる方のためにエラーメッセージの一部を書いておく。
vmhgfs-only/fsutil.h expected 'gid_t' but argument is of type 'kgid_t'
vmhgfs-only/file.c
incompatible type for argument 4 of 'HgfsSetUidGid'
HgfsAioRead
implicit declaration of function ' generic_file_aio_read'
HgfsAioWrite
implicit declaration of function ' generic_file_aio_write'
解決
VMwareTools のインストールに失敗していた。
VMwareTools のインストール中に、
エラーが出ていないことをちゃんと確認すること。
画面が流れてしまうし、
YES とか NO とか入力しなくてはいけないのでログをファイルに落とせないが、
エラー全部は見えなくても、
何か失敗していることはわかる。
VMwareTools を解凍して、vmhgfs-only のディレクトリで、
エラーが出なくなるまで、ソースの修正と make を繰り返す。
エラーが出なくなったら、それをインストールして解決。
make の仕方などは、以下のページを参照。
システムエンジニア☆あきき VMWareでhostとのファイル共有ができなくなって…対処
http://akiki2starlet.blog.fc2.com/blog-entry-7.html
make の前は必ず make clean を実施。
ソースの修正は、以下のページから、
自分のカーネルバージョンに合うものを探す。
パッチになっているが、大した量ではないので、
vi で手で直すのも可能。
vmware-tools-patches/patches/vmhgfs at master ・ rasa/vmware-tools-patches ・ GitHub
元のソースは必ずバックアップしておく。
確認
/mnt/hgfs 以下にマウントされるだけではダメで、
ファイルの送受信をしてみる。
それでエラーが出て何度かソース修正をやり直した。
以下のページに従って、VMwareTools の動作確認を行う。
VMwareToolsの動作確認・起動はどのようにすれば良いですか。 | ニフティクラウド
http://cloud.nifty.com/cs/catalog/cloud_faq/catalog_120416000931_1.htm
そのた情報
VMwareTools のバージョン確認方法
$ /usr/bin/vmware-toolbox-cmd -v
VMwareTools サービスの再起動方法
$ sudo service vmware-tools restart
VMwarePlayer のメニューからダウンロードした VMwareTools の
iso イメージは、ホストの以下のディレクトリにある。
以下は linux ゲスト向けのファイル。
C:\Program Files (x86)\VMware\VMware Player\linux.iso
VMwareTools は以下からダウンロードできる。
CDS Repository - /var/www/public/stage/session-43/cds/vmw-desktop/player
exe がダウンロードできるので、以下のページを見ながら解凍も可能。
解凍をくりかえすと、中から linux.iso が出てくる。
VMware Tools (9.2.2) をダウンロードする。 - 量産メモ
http://d.hatena.ne.jp/RMS-099/touch/20121109/1352452591
VMwarePlayer のメニューから VMwareTools のインストールに失敗した場合は、
この iso イメージを cdrom としてマウントしたら
インストールできるんじゃないだろうか。
これまではメニューからのインストールによく失敗していて、
面倒で放置していたのだが、今度失敗したらやってみよう。
VMwareTools は日々修正され、ビルドされているぽい。
前日ダウンロードしたものと、今日のビルドバージョンが違うということがあった。
また、ダンナも同じバージョンで新規インストールして試してくれたが、
ホストもゲストもまったく同じなのに、エラーは出ず、問題なく動いたらしい。
日によって挙動が違うのだろうか(謎
↧
[VMware]ホストとファイル共有ができないのを解決
↧
データ分析職の素養について
データサイエンティストというかデータ分析職に就くための最低限のスキル要件とは - 銀座で働くデータサイエンティストのブログ
上記はいつもお世話になっているブログです。
難しいことを簡単に書いているので、
いつも本当にすごいと思います。
難しいことを難しく書くのは、むしろ簡単だと思うんですよね。
(wikipedia なんかは良い例かと)
で、上のブログを見て、私も考えました。
現在、私は主にデータ分析ぽい業務をしています。
開発をやっていたはずなのに、
どういうわけだか、こんな分野にいます。
部署としては開発の部署なので、、
「データ分析を元にしたシステム開発」という感じ。
なので、バリバリにデータ分析しているわけではありません。
バリバリ分析の部署もありますが、
そちらの人たちは本当に研究者です。
私の部署での業務では、こんな感じです。
・お客さんの要求と、処理速度と精度の兼ね合いを見て、
「ちょっと精度は落ちるけど、速いからOK」とかを考える
・少数の人しか理解できないようなステキ理論より、
「説明されれば中学生でもわかる」レベルの実装仕様を考える
(難しい理論は、実装も難しいし、テストも難しいので)
実装を見据えた分析をするわけです。
時には、プロが見たら卒倒しそうな邪道な実装をすることもあります。
でも、決められた期間で作ることができて、
要求される速度で動いて、実装もテストもメンテも楽なら、
お客さんはそれでOKなわけです。
お客さんが欲しいものは、別にステキ理論ではなくて、
ちゃんと動くものです。
上司たちは、データ分析ができる人を増やしたいようです。
バリバリ開発するでもなく、出世も興味がないけれど、
ほどほどなんでもやります、みたいな私のようなお姉さん社員が
データ分析できるといいなぁと思っているようです。
(そりゃ戦力になってくれたら上の人たちとしては嬉しいよね)
でもなかなか人材が見つかりません。
私個人が考えている、データ分析チームに来てくれるといいなぁと
思っている人について、書いてみます。
(いよいよタイトルの内容!前置き長い!)
(1)地道な作業が苦でない人
データ分析はかなり地味で、単純作業も多いです。
そういうのが合わない人は多いみたいです。
明確な完成というのもないし、
完成しても何かが動くわけではないので、
プログラム書くよりも、達成感が少ないんですよね。
(2)「ベクトル」という言葉に嫌悪感がない人
「ベクトル」という言葉はよく出てきます。
「特徴量」とか。
私は根っからの文系なので、
理系の人はみんな「ベクトル」なんてちょろいのだと思っていました。
でも、そうでもないらしくて、
理系の人でも、「ベクトル」と聞くとテンションがダダ下がるという人が
結構いるみたいです。
先日も、ベクトルの内積の説明を1分ほどしたら、
みるみる目がウツロになっていく人がいて、
あーそうなんだーと思いました(笑
また、文系の人でも、
数式にあまり抵抗がない人が良いです。
私は抵抗があった方ですが、見慣れると見慣れます。
でも式の意味はいまだに全然わからないのですが(笑
(3)スクリプトが書ける人、コマンドラインが怖くない人
データ分析では、よく DB を使います。
ので、SQL が書けると良いです。
Hadoop HDFS なんかだと ruby を書くのでしょうが、
まだ RDB が多いので、 SQL のほうが出番が多いです。
ほぼコマンドラインなので、そういうのが怖くない人が良いです。
また、データ整形は多いです。
全部のデータを10倍する、みたいなものも多いです。
perl でも ruby でも python でもいいので、
簡単なスクリプトが書けると良いです。
書けなくても良いので、「そういうの無理です」と言わない人が良いです。
excel もよく使います。
excel は勝手に表示形式を変えてしまう
(年月日形式とか、小数点以下を勝手に減らしたり)ので、
エディタで操作することも多いです。
ノートパッド以外の、秀丸でもサクラでもterapadでもいいので、
使えるエディタがあると良いです。
データは文字コードもバラバラだったりするので、
そういう時も、エディタは必須です。
また、大きすぎて開けないファイル、というのも良くあります。
そういう時は、more や less や head や tail などを駆使して、
ファイルの中を見るということもあります。
やっぱりコマンドラインです。
SPSS などが使えることが重要と思う人もいるかもしれませんが、
数年前に一緒に仕事をしたデータ分析見習いの人は、
SPSS は使えるけど、データ前処理が全然処理できなかったので、
結局、分析ではそれほどの戦力になりませんでした。
(分析結果報告書を書く段には、その人の知識が大活躍しましたが)
世の中、キレイなデータのほうが少ないので、
SPSS などに入れるためのデータを作る作業は、ほぼ必ず発生します。
そのために、Python や SQL やコマンドラインを使います。
得意な人に分担してもらうこともできますが、
自分でできた方が、自分で考えた分析にすぐ着手できます。
上のほうでも書きましたが、
中学生でもわかる、ちゃんと動くシステムが欲しいわけで、
そういう時は、生データをあれこれして、
あれこれやってみる、という Try&Error が多いのです。
(4)学ぶことに抵抗のない人
初心者であるほど、ほぼ勉強ばかりです。
どんなジャンルでも勉強は必要ですが、
このジャンルは特に、統計とか、学校の勉強風の内容が多いです。
ので、学ぶことが多くてうんざりする人や、
確率統計だけは仲良くなれる気がしないという理系の人は、
あまり向かない気がします。
個人的には、統計の知識はあると良いし、
機械学習の知識もあると良いけど、
そういうのはOJTで覚えていけば良いと思っています。
それよりも、その人の性格とか好みとかが影響するなぁと思っています。
ちなみに、ウチのバリバリ分析部署の人たちは、
大学で研究していた院卒の専門家ばかりなので、
上記ブログの「最低限」でも全然足りないかも(笑)
XXX
ブログのタイトルと合わなくなってきたかもなぁと、
大分前から思っていました。
でもま、いいか、みたいな。
プログラムを書くのは好きなので、
仕事とは別に、ちょこちょこ書いたりしています。
ムダにAndroid Studioとか入ってるし!
↧
↧
人工知能の夢
「人工知能に対する楽観的な妄想」はいつか来た道 - 銀座で働くデータサイエンティストのブログ
人工知能、AI とか言われる分野にン十年前からいるので、
これを読んで、あーそうだそうだと色々思った。
そのあたりをだらだらと。
昨今、「人工知能」がブームになっている。
たぶん、Deep Learning (深層学習)のお陰だろうと思う。
ざっくりに言うと、
意外に簡単なとうに枯れたような仕組みで、高い精度の画像認識ができた!
というものである。
その仕組みは画像認識でなくても使えるよね!というわけで、
ブームになっている
さらにその陰には、マシンパワーやネットワークの向上や、
計算の分散方法の研究成果なんかがあると思う。
でも、その前は長いこと陽の目を見ない冬の時代が続いていた。
人工知能の先には、やっぱりロボットの夢がある。
日本人は御一新の前から、からくり人形なんかが大好きなわけだが、
欧米人は人間に似せた人形(ひとがた)を作ることに、
なんだかものすごく抵抗があるらしい。
人を作るのは神の領域であって、侵すことは禁忌なのだろう。
Deep Learning が出てくるまで、
脳の機能を模倣しようとしたニューラルネットワークの研究が
流行っていなかったのも、
心理的抵抗があったのじゃないかと思う。
(Deep Learning の仕組みの基本はニューラルネットです)
しかし、Deep Learning は突然出てきたわけではない。
冬の時代にもニューラルや人工知能の研究を継続してきた人がいたからだ。
売れないものに喜んでお金を出すような会社は、あまりない
(会社でない、例えば国立の機関などでも、お金はそちらに流れません)
だから、そういう研究者は、
別の研究の陰で、研究費をやりくりしながら、
こっそりと人工知能の研究をしてきた。
研究者が「そこに夢がある」と思うからこそ、頑張ってやりくりする。
たぶん、色んな所に色んな研究者がいて、色んな夢を見ているのだろう。
中には、ずっと冬のままで、枯れてしまう夢もあるのだろう。
いま、Deep Learning はバブルと言っていいほど、もてはやされている感がある。
そして以前にも、カオスだの、ファジィだの、複雑系だのと、
もてはやされた言葉がたくさんあった。
20 年以上前に購入したウチの洗濯機にも
「ニューロ」というボタンがある。
白物家電にボタンが付くくらい、それらの言葉は消費された。
そうしてそれらの言葉は、昨今では研究分野以外ではほぼ出会わない。
人工知能や Deep Learning も、そのように消費されていくのかなと思う。
私個人も、リンク先のページと同感で、
人工知能はまだまだ人を脅かすほどの「知能」はないし、
私が生きている間には
電気羊の夢を見るアンドロイドは完成しないだろう。
でも、世間の人々の「楽観的な妄想」は嫌いではない。
それは「あの頃、夢見ていた21世紀」なんだろうなと思う。
↧
[win][R] libsvm のグリッドサーチ
libsvm (e1071) のグリッドサーチで2点ほど。
実行環境は windows です。
グリッドサーチの分割方法
グリッドサーチの際、常に分割は同じなのか。
例えば、 cross=3 と指定して、複数回実行したら、
常に同じデータが同じグループになって実行されるのか。
毎回ランダムなデータがランダムにグループ分けされて実行されるのか。
ソースを見てみたところ、
R で書かれたソース(tune.R)では、特にランダマイズされていなかったが、
C で書かれたソース(Rsvm.c)では、ランダマイズされていた。
windows で実行する場合は、
多分 R ファイルを実行するのではなく dll を呼んでいると思うので、
ということであれば、毎回ランダムなのだろうなぁと思う。
想像でしかないのだが。
グリッドサーチの結果の正答率
SVM のチューニングのしかた(2) - ほくそ笑む
http://d.hatena.ne.jp/hoxo_m/20110325/p1
で、以下のようにある。
グリッドサーチの結果としてベストパラメータを出力しています。上記のプログラムを実行すると、結果は下記のように出ました。
- best parameters:
gamma = 0.1 ; cost = 1 ;
accuracy: 97.33187 %
gamma=0.1, cost=1 の組合せのとき、正答率 97.3 % を出していることがわかります。
gamma=0.1, cost=1 のときに、cross=3 であれば、
3回の svm が実行されていると思うのだが、
accuracy は一体何の数字なのか。
割とあっさり 100% が出たりするが、
3回実行してそう簡単に 100% が出るとは考えづらいので、
加算平均ではないような気がする。
てことは、3回の中の最高正答率なのかなという気もするが、
100% のときは dispersion (分散)も 0 と出るので、
やっぱり加算平均かもしれない。
なわけで、ソースを見てみた。
結果、3 回実行の中での平均値を選択していた。
それはそれでなんかびっくり。
3 回実行を更に複数回す設定 (nrepeat) をしている場合は、
nrepeat 回の中での最小エラー率が選択されるので、
やっぱりエラー率は 3 個得られて、
そこから平均を出すぽい。
あっさり 100% が出ても、
平均を取った結果の 100% なら、
ある程度の余裕を持って識別境界が決定されていて、
オーバーフィッティングの心配はないと思っていいのかな。
↧
[python][win7]pip と proxy
windows7 に chainer 入れちゃうぜ!とテンション上がったが、
入れようとしたら入らないよ。
proxy のエラーだよ。
D:\Python27\archives\chainer-master>pip install chainer
Retrying (Retry(total=4, connect=None, read=None, redirect=None)) after connecti
on broken by 'ProxyError('Cannot connect to proxy.', gaierror(11004, 'getaddrinf
o failed'))': /simple/chainer/
Retrying (Retry(total=3, connect=None, read=None, redirect=None)) after connecti
on broken by 'ProxyError('Cannot connect to proxy.', gaierror(11004, 'getaddrinf
o failed'))': /simple/chainer/
Retrying (Retry(total=2, connect=None, read=None, redirect=None)) after connecti
on broken by 'ProxyError('Cannot connect to proxy.', gaierror(11004, 'getaddrinf
o failed'))': /simple/chainer/
Operation cancelled by user
環境変数 HTTPS_PROXY も HTTP_PROXY も指定してあるのだが。
でも結果的に間違いだった。
今まで大丈夫だったのは、ソフト側で対応しててくれたんだなぁ。
失敗
set HTTP_PROXY=http://username:passwd@proxy.example.com:port/
set HTTPS_PROXY=https://username:passwd@proxy.example.com:port/
↓
成功
set HTTP_PROXY=http://username:passwd@proxy.example.com:port
set HTTPS_PROXY=https://username:passwd@proxy.example.com:port
このくらい気を利かせてくれと言いたい気もする。
これで挫けてしまったので、
Ubuntu に chainer 入れようと試みたり、
(会社の LAN のせいで、VM を NAT で接続できず、apt-get できなくて挫折)、
いや caffe にするかとか、
( GPU が AMD だから CUDA が使えないのでは。
つかそもそも caffe が win に対応してねーわ。
VM の Ubuntu は前述の理由で apt-get できないし…)
いろいろ紆余曲折して2日も無駄にしてしまった…(;´Д⊂
↧
↧
[Ubuntu] Unity Launcher のアイコンを復活させる
三行で説明
ランチャの CD のアイコンを間違えて削除しちゃったので、
ツールなしでコマンドだけで
復活させました。
はじめに
OS : Ubuntu 14.04 LTS デスクトップ版
共用の Ubuntu14 を使っていて、
CD アイコンの右クリックメニューで
間違えて「Launcherへの登録を解除」を選択してしまいました。
「取り出し」のすぐ上にあったので、つい手が滑って。
がーん。
CD を入れると、
自動マウントされて、ランチャにアイコンが出ます。
このアイコンの右クリックメニューで CD を取り出します。
解除してしまうと、ランチャにアイコンが出ません。
アイコンが出なければ、
右クリックメニューでの CD 取出しができません。
自分のマシンなら eject コマンドで出すのですが、
Linux に大層不慣れな2年生君が勉強も兼ねて構築しているマシンなので、
元に戻してあげたいわけです。
ついでに、余計なアプリも入れたくない。
自分の普段使い Ubuntu はコマンドラインのみのサーバ版なので、
デスクトップ版の GUI の勝手がわかりません。
Linux はウィンドウマネージャとランチャとファイラが
全部違うアプリ名だったりするので、
昔からわかりづらくて苦手で、
再インストールが必要なほどめちゃめちゃにしたこともあり、
なんとなく避けて通ってきました。
でもなぁ LASER5 Linux とかの頃だしなぁ(懐)
今はもうキレイに洗練されてるんだろうなぁ。
この画面の横のランチャは GNOME 上のユーザインタフェース Unity の中の
Launcher という名前の機能だそうです。
通常のアプリをランチャに登録
通常のアプリを登録する場合は、
起動するとランチャにアイコンが表示されるので、
右クリックメニューから「ランチャーに常に表示」を選択すれば
登録されます。
UbuntuでRails3.2.3 (2) 端末アプリを使いやすくする
http://www.supportdoc.net/topic/linux/ubuntu-ror2.html
自分で作ったコマンドなどの場合は、
以下のページが参考になります。
Unityランチャーに自分でインストール/ビルドしたアプリケーションを登録する - reppets.log.1
http://d.hatena.ne.jp/reppets/20111109/1320846292
Unity のランチャに登録する方法 (追記: Lubuntu でも) - 見上げれば、空
http://tohka383.hatenablog.jp/entry/20120331/1333156658
でもいずれもアプリやソフトなどがある場合の方法です。
CD は入れたときだけアイコンが表示されるので、
固定のアプリがあるわけではないです。
そもそも、アイコンが表示されなくなった場合は
この方法ではダメですね。
一般的な直し方:dconf-editor を使う
Launcher の設定は dconf に保存されています。
dconf は windows でいうとレジストリみたいなものだそうで、
GNOME 関係のアプリは dconf に設定を保存します。
設定はバイナリで保存されており、
編集には専用エディタ dconf-editor のインストールが必要です。
dconf については、以下のページが、絵が多くてわかりやすいです。
Ubuntu dconfエディター その1 - dconfについて・インストールと使い方 - kledgeb
http://kledgeb.blogspot.jp/2012/12/ubuntu-dconf-1-dconf.html
Launcharの登録を解除したアイコンを復活する関係は、
日本語のページには見当たらなくて、
以下のページがどんぴしゃです。
unity - How can I remove launcher drive icons? - Ask Ubuntu
http://askubuntu.com/questions/195988/how-can-i-remove-launcher-drive-icons
コマンドだけで直す:gsettings を使う
Unity は GNOME 関連のアプリということで、
gsettings コマンドでも設定ができます。
dconf-editor と同じ設定ができます。
以下のコマンドで、設定の一覧(設定項目、設定値)が出力されます。
$ gsettings list-recursively
で、Unity 関連だけ見てみます。
さらに Unity の表示/非表示に関連した項目だけを見てみます。
$ gsettings list-recursively | grep Unity | grep list
com.canonical.Unity.Devices blacklist ['-UDF Volume']
これだー!この blacklist だー!
この blacklist の設定値を変更して、リストを空にします。
$ gsettings set com.canonical.Unity.Devices blacklist "[]"
結果を確認すると、空になっていますね(3行目)。
$ gsettings list-recursively | grep blacklist
com.canonical.unity-gtk-module blacklist @as []
com.canonical.indicator.sound blacklisted-media-players @as []
com.canonical.Unity.Devices blacklist @as []
CD を入れてみると、ちゃんとアイコンが出ました。
やったー!
再起動や再ログインなどは不要でした。
余談:gconf, dconf, gsettings, dconf-editor
Gconf, Dconf, Gsettings and the relationship between them - Ask Ubuntu
http://askubuntu.com/questions/249887/gconf-dconf-gsettings-and-the-relationship-between-them
いったいどれを使えばいいの?どういう関連なの?という質問を持った人。
そうだよね、そう思うよね。
GNOME3 を使っているなら、
gconf とか dconf とかは直では触らずに、
dconf-editor や gsettings を使うべきだよ、という話のようです。
この2つは、どちらを使ってもいいみたい。
redhat のページに説明があったわ。
9.1. 用語の説明: GSettings、gsettings、および dconf
↧
ネットワークのトラブルは寝ると治る
…というのは割と真実。
体験から。
XXX
会社マシンで VMware Player を使っていて、
ネットワークはブリッジ接続にしている。
本当は NAT にしたいのだが、
NAT にすると、出たパケットが戻ってこない。
社内 LAN は 192.168.*.* を全部使っている。
自部署 LAN と違う LAN の 192 系を振ると、
同じ名前のやつが社内の別の部署にいるから、
そっちに行っちゃうのだろう。
VM に 192 系以外を振ることができれば良いのだが、
VMware Player ではどうもダメっぽい。
有料版だと 172 系も振れるみたいなのだけど。
なわけで、わざわざ VM 用に自部署 LAN の 192 系 IP を1個取ってある。
(ネットワーク管理者から払い出してもらわなくてはいけないので、
申請書を出したりなんだり、結構面倒くさいのである)
VM (Ubuntu) から久しぶりに apt-get してみたら、
unreachable と怒られた。
この前まではできていたので、まったく謎。
ゲスト OS から見てみると、proxy までは ping も通るのだが、
LAN の外に出られないぽい。
社内マシンであれば、名前解決はできている。
社外は名前解決ができない。
ホスト OS からはいずれも問題なし。
ホスト OS の Wireshark で見てみたところ、
ゲスト→ホスト→外は良いのだが、
戻りが、外→ホストで止まっている。
こういうとき考えられるのは、ウィルスチェッカやファイアウォールなのだが、
Windowsファイアウォールの設定は変えていないし、
いったい誰が閉じているのやら。
スキルがなくて追えない。
そして翌日、出社してすぐ試してみたところ、
ウソのように apt-get がするりと通った。
まったく謎。
XXX
ネットワークのトラブルは、
時間が経つと解決されることが結構ある。
どこかのサーバで
ある一定時間でキャッシュがクリアされたり、
夜中に定期リブートされたりするのだろう。
もしくは端末をリブートしたことで、
何かに刺さってたサービスが正常動作になったり。
端末からすると、なぜか治った、という現象に見える。
というわけで、ネットワークのトラブルは寝ると治る。
急がないならば、
日を置いて試してみるのも手なのよね。
↧
[python]cifar10の画像をbmpでファイル出力
自分メモ
すごい俺得
cifar10データセットは以下
CIFAR-10 and CIFAR-100 datasets
bmpでファイルに保存する、というソースが意外に見つからない。
extract_cifar10_bmp.py
import cPickle
import argparse
from PIL import Image
import numpy
# 引数で、cifar10ファイルと、何番目のbmpを取り出すか指定する
# ex) extract_cifar10_bmp.py cifar-10-batches-py/data_batch_1 0
# data_batch_1.0_leptodactylus_pentadactylus_s_000004.png.bmp を作成
parser = argparse.ArgumentParser()
parser.add_argument('dfile', help='cifar10_file')
parser.add_argument('nth', help='number of image(0-)')
args = parser.parse_args()
dfile = args.dfile
nth = args.nth
# cifar10ファイルを開いて読み込む
fh = open(dfile, 'rb')
pickles = cPickle.load(fh)
fh.close()
one_pickle = pickles['data'][int(nth)] # 指定番目の画像データ
# ↑ 3072 要素の配列 ([R....G....B...]のように並んでいる)
# 出力ファイル名作成
outfile = dfile + '.' + nth + '_' + pickles['filenames'][int(nth)] + '.bmp'
# 3072の一次元配列を、3x32x32 の三次元配列に変換
# [ [R(32x32)], [G(32x32)], [B(32x32)] ] の形式になる
3darr = numpy.reshape(one_pickle, (3,32,32))
# RGB のように並べる
# [ [ RGB ... 32個], [ RGB ... 32個],... 32個 ] の形式に変換
rgbarr = numpy.rollaxis(3darr, 0, 3)
# PIL に変換してファイルに出力
pilImg = Image.fromarray(rgbarr, 'RGB')
pilImg.save(outfile, 'BMP')
print outfile
遅ればせながら、ようやくpythonを書き始めたので、
まだエラー処理とかわからないんです(笑
追記:
pngで保存する場合は、以下が参考になりそう。
https://github.com/mitmul/chainer-cifar10/blob/master/dataset.py
87行目あたりとか
↧
[emacs] いろいろ色を変える
PuTTY で Ubuntu に接続して、
emacs 起動してるんだが、
背景が黒いので、青い字が読めない。
見づらい。
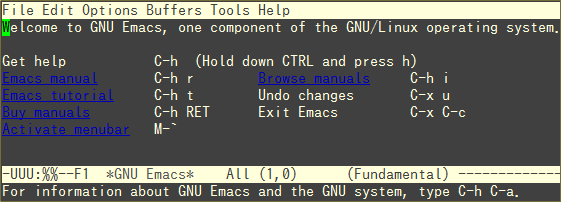
なので、emacs の色を変えてみた。
PuTTY の設定で背景を白にすればいいのだろうけど、
そういうことじゃないです。
目が弱いので、背景は黒がいい。
そして emacs の設定を変えたいわけです。
参考:
(1)
Emacsの背景色の設定方法をまとめてみた - @kei10in の日記
http://kei10in.hatenablog.jp/entry/20101101/1288617632
(2)
Emacsでgitのdiffを見るときのfont colorを変える - a-bit’s blog
http://a-bit.hatenablog.com/entry/2015/05/04/234918
(3)
GNU Emacs Lisp Reference Manual: Defining Faces
http://www.gnu.org/software/emacs/manual/html_node/elisp/Defining-Faces.html#Defining-Faces
(4)
GNU Emacs Lisp Reference Manual: Face Attributes
http://www.gnu.org/software/emacs/manual/html_node/elisp/Face-Attributes.html#Face-Attributes
設定方法には複数あるようだが、
参考(1)のページを見て、
custom-set-faces での設定がおすすめられていたので、それにする。
以下のような感じのを、.emacs に追記する。
(custom-set-faces ;; <- (a)
'(cursor ;; <- (b)
((((class color) (background dark)) ;; <- (c)
(:background "green"))))) ;; <- (d)
(a) は関数名なので、そのまま書く
(b) は face 名で、これをどのように得るかというと、
参考(2)にあるように
色を変えたい文字にカーソルを合わせ,
M-x eval-expression RET (get-char-property (point) 'face) RET
で名前を取得できる.
Windows のキーボードでやるときは
M-x eval-expression RET
の部分は
Esc :
と入力するよ。
これで face 名がわかる。
表示されたあと、なにかキー入力すると、
表示された face 名が消えちゃうので、
setq して変数にバインドしておくといいかも。
(c) はどんなときに色を変えるかという条件部。
最新の日本語のページを見つけられなかったので英語ページだが、
参考(3)のページに書いてある。
複数条件を書くと AND で判定するっぽい。
(d) は設定項目と色。
設定項目は、参考(4)のページに書いてある。
設定できる色は参考(2)にあるようにすると、
その端末で使える色の一覧が出る。
好きな色を探す
M-x list-colors-displayで色とその名前を調べることができる.
8色しか使えなかったがーん。
最後に、現在のところの設定。
青くて見づらいのを見つけたら追加していくよー
(custom-set-faces
'(font-lock-builtin-face
((t (:background "blue" :foreground "white"))))
'(font-lock-function-name-face
((t (:background "blue" :foreground "red"))))
'(button ((t (:foreground "cyan" :underline t))))
'(minibuffer-prompt ((t (:foreground "cyan"))))
'(comint-highlight-prompt ((t (:foreground "cyan"))))
)
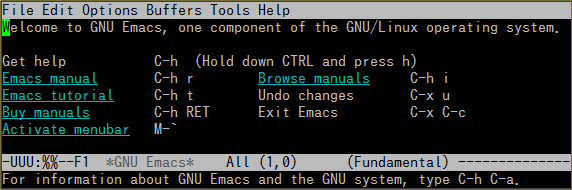
これなら読める
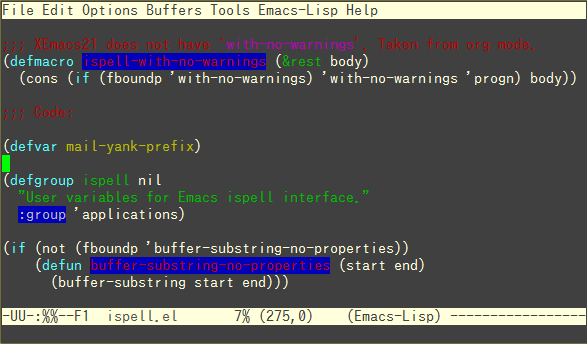
色のセンスとか気にしない
↧
↧
高城高「函館水上警察」
高城高「函館水上警察」(東京創元社)
図書館で棚の前を通りがかって、タイトルにひかれて借りてしまった。
まったくの偶然の出会いである。
函館出身なもので、函館と書いてあると気になってしまうが、
函館を舞台にした作品は、数はあまり多くはない。
数は多くないのに、
箱館戦争関係は食傷だし(幕末も興味ない)、
ノスタルジック青春群像は
舞台が函館である必要性を感じないので、あまり興味がない。
というわけで、手に取る作品は本当に少ない。
同じ作家の作品ばかり読んでいると読みつくしてしまうので、
時々、このように飛躍をすることがある。
表紙のイラストレーターで借りてみたり(中島梨絵さんステキー!)
新聞の書評を参考にしてみたり、
お気に入り作家の作品紹介本をたどってみたり、
お気に入りのweb論客のおススメ本をたどってみたり。
で、図書館の棚でこの本に出会った。
書かれているのは、私の知っている函館だけど、
ちゃんと知らなかった函館だった。
フィクションではあるのだが、
たぶん、本当にこういう風景が広がっていたのだと思う。
矢車草やライラックの咲く民家の庭。
ハリストス正教会の薄暗い室内。
五島軒の白い外壁。
イギリス領事館のこじんまりした佇まい(実は現在のとは違うらしい)。
ロシア領事館の入ってすぐの豪華な階段の手すりと、
サロンから見おろす函館港の景色。
(1996年までは研修施設として宿泊できたので、何度も宿泊した)
私が知っているのは「文化財」としてのそれらだ。
でも当時は文化財ではなくて、
函館に生活する人々の暮らしに身近なものだった。
五島軒でロシアンな洋食を食べたり、
宝来町の花町にくりだしたり、
基坂(もといざか、と読む)をあがって市役所に行ったり、
亀田川の水を汲んで飲料にしていたり、
ラッコの毛皮が金森倉庫に運び込まれたり、
そんな生活が確かにあったはずだ。
この本で書かれている函館を知るまで、
私はそんな景色を想像したことがなかった。
もったいないことをしたなと思う。
ま、まだ10代前半だったから、私には難しかったと思うが。
主人公は、私のおじいさんのおじいさんくらいの年齢ではないかと思う。
ひいひいおじいさん、かな。
北海道に入植したてのひいひいおじいさんと、
ひょっとしたら、街ですれ違ったかもしれない。
この本を手に、函館に帰りたくなった。
きっと新しい景色が見えると思う。
↧
HP Envy 700-060jp オーディオドライバの入手方法
「HP ENVY 700-060jp に Windows7 64bit をインストール」の続き
http://xiaoxia.exblog.jp/18756770/
そもそも
windows の調子が悪い。
たぶん、レジストリいじりすぎた。
どんなアプリでも「名前をつけて保存」をするとフリーズするし、
アクセスできるファイルサーバとダメなのがあるし、
アクセスできてもファイルサーバとのフォルダのコピペができない。
(リモートにコピペも、ローカルにコピペもできない)
そして1日4回くらいフリーズする。
memtest では異常なし。
イベントビューワーで見ても、特に異常は出ていない。
HDD のコネクタとメモリの挿し直しもしたが治らない。
たぶん、レジストリいじりすぎた。
再インストール
思い切って再インストール。
OS はプログラムとは別ドライブに入れてあるので、
OS だけ再インストールしても
元の作業環境にするのは比較的簡単。
C:\users\自分\ とかだけはバックアップ取っておいて、
再インストール後は、ドライバ入れて、
office 入れて、会社指定のソフトを入れて、
バックアップ取っておいた c:\users\自分\ を一部書き戻せばOK。
ドライバは前回インストールしたときのが全部残してある。
所要時間3時間で終了。
定時直後に始めて、その日のうちに元通りって嬉しいー(^-^)
(windows update は仕掛けて帰宅したら 300 件以上当ってたけどw)
と思ったが、気づいたら音が出ない。
現在、音声分析の業務をやっているので、
音が聞けないと困る。
以前は、コンパネに Beats Audio のアイコンがあったので、
何かをインストールしたのだろうが、exe が残っていない。
というわけで、ドライバ探し。
ドライバ見つけた
HP Envy 700-060jp は windows8 モデルなので、
公式のドライバでは、OS が違っていてインストールできない。
同時期の類似機種で、以下の条件のものがないか探してみた。
・Windows7 プレインストールモデル
・チップセットがIntel Z87 Express(オーディオはチップセット内臓なので)
・with Beats Audio な機種
ググってみたら、先頭に出てきたのが HP Envy 700-270jp だった。
前述の条件をすべて満たしているので、
このドライバなら入れても大丈夫。
というわけで、HP の公式からダウンロード。
下の公式サイトで、Envy 700-270jp で検索。
http://support.hp.com/us-en/drivers
オーディオドライバとして2件表示されるうち、
日付が新しいのが以下。
detail を見れば日付がわかる。
http://ftp.hp.com/pub/softpaq/sp65001-65500/sp65099.exe
というわけで、問題なく音が聞けるようになったし、
コンパネにも Beats Audio のアイコンが入った。
めでたしめでたし。
↧
[R][e1071]libsvmのモデルのインポート/エクスポート
libsvm には write.svm という、モデルを出力する関数があるけれど、
逆の read.svm は実装されていない。
世界中で load model はどうするの?、という質問がたくさん出ている。
僕の github のコードを使ったらいいよ、とか
そんなんばっかりで、あんまりばちっとした回答が書いてあるページがない。
では、モデルのインポート、エクスポートはどうするか。
write.svm は人が読める形式で出力するための関数のようだ。
ので、write.svm でエクスポートしてもダメ、というのが答えかも。
この形式をインポートしても良いけど、
わざわざ人が読める形式にしてあるので、
読み込んでもたぶん dog slow だろう。
というわけで、普通にオブジェクトのバイナリダンプが良いみたい。
確認してみたけど、ダンプ前後でモデルは変わらなかった。
library("e1071")
svm_model <- svm(Species~., data=iris)
modelfile <- "model.svm"
save(svm_model, file=modelfile)
load(svm_model, file=modelfile)
↧
[firefox]cookieフィルタを一括指定
はじめに
webブラウジングをする際、
自分に不要なcookieは拒否したい派です。
サービスを使うのに必要最低限のcookieだけを取得したいです。
普段は基本的にすべてのcookieを拒否していますが、
新しいサービスを使うときは
どんなcookieが必要なのかわからないので、
とりあえず全部のcookieを取得して、
それから取捨選択します。
自分には不要ぽいのは今後はずーっと拒否したい。
以前のfirefoxは、
そのつどプロンプトが出てきて、
取得するcookieと保存期間を指定できたのですが、
そのプロンプトを出す設定がなくなりました
(firefox ver.44くらいから?)。
network.cookie.lifetimePolicy=1 に設定すると出るらしいのですが、
設定してもプロンプトが出ません。
firebugなんかで食わされたcookieを見てみると、
たくさんのcookieが並びます。
firefoxのcookieフィルタは指定が1件ずつなので、
これをすべて拒否指定することを考えると、気が遠くなります。
ブラックリストを一括で指定できたらいいのに。
アドオンを探してみましたが、見当たりません。
そういうニーズないのかな。
ちゃんとcookie取得するなんて、良い人が多いんだなぁ。
というわけで、自分の環境で指定する方法を見つけてみました。
方法を3行で説明
・cookie を取得したくないブラックリストcsvを作成
・アドオン SQLite Manager を使用
・自プロファイルディレクトリ以下 permissions.sqlite にインポート
SQLでcsvを突っ込むという作戦です。
上手く行きました。
大分アレだけど。
方法を詳細に説明
■【1】アドオン SQLite Manager をインストール
https://addons.mozilla.org/ja/firefox/addon/sqlite-manager/
他の方法は試してません。
他の方法が良い場合は、ごめんなさい。
■【2】SQLite Managerで設定テーブルの最大IDを取得
ブラックリストの項目に連番を付与する必要があります。
ので、現在の最大 ID 番号を見つけておきます。
念のため、ここで
自プロファイルディレクトリ以下の permissions.sqlite をコピーして
バックアップを取っておきます。
DBを直接いじるので、firefoxが起動しなくなる可能性もあります。
SQLite Manager を起動し permissions.sqlite を開きます。
左ペインで、Tables -> moz_perms を選択します。
「参照と検索」タブをクリックして、最後のデータを見ると、
現在の最大の ID が分かります。
「SQL実行」タブで、以下のように実行してもいいです。
SELECT max(id) FROM moz_perms;
この場合 973 ですね。
■【3】ブラックリストcsvを作成
以下のような感じのブラックリストcsvを作ります。
先頭の ID カラムは、前項で得た ID 最大値より大きい数値から始めて
連番を振ってください。
974,http://blacklist.example.com,cookie,2,0,0,0
975,https://blacklist.example.com,cookie,2,0,0,0
4カラム目の「2」は「拒否」の意味ぽいです。
詳細は不明です。
同じドメイン名で http/https の2つの設定をするみたいですね。
■【4】SQLite Managerからインポート
メニュー「データベース」→「取り込み」で、
「Import Wizard」タブが開きます。
ブラックリストcsvファイルを選択し、
・データが取り込まれるテーブルの名前は「moz_perms」
・区切り文字は「コンマ」
・クオートなどは「None」
を指定して、「OK」ボタンを押します。
"main"."moz_perms"にインポートしてよいかと聞かれるのでOKします。
追加した設定行数が表示されるのでOKします。
■【5】できあがり:確認
firefox を再起動すれば設定が反映されています。
設定からcookieフィルタを見ると、ちゃんと入っています。
↧
↧
sox statのマニュアル
先月まで見ることができた
SoX, SoXI, soxformat マニュアルページ日本語訳
のページがなくなっていたので、
自分がコピペしておいた stat の部分だけ貼っておく。
自分でメモを追加した部分もあり。
stat [-s scale] [-rms] [-freq] [-v] [-d]
ex)
sox.exe test.wav stat
標準エラーに出力されるので、こんな感じで使うのがよいか
sox.exe test.wav --null stat 2>&1
注:サンプル間の差分の情報は、多チャンネルには対応していない。
-s オプションは与えられた値で入力データをスケールする。
スケールのデフォルト値は 2147483647 (つまり32ビット符号付き整数の最大値)。
内部的には常に符号付きlong PCM データとされる。
そして値は与えられた値に関連している。
-rms オプションは、出力するすべての平均値を、(普通の加算平均でなく)二乗平均平方根に変換する。
-v オプションは 'Volume Adjustment' だけ出力する。
-freq オプションは、統計情報の代わりに、入力のパワースペクトラム(デフォルト4096個ずつ)を計算する。
モノラルチャンネルの音声ファイルのみに使える。
-d オプションは、soxの内部バッファで、32ビット符号付きPCMデータ音声を16進でダンプしたものを表示する。
これは主に、soxの異なるプラットフォームバージョン間で発生するエンディアン問題を見つけ出すのに役立つ。
音声の時間領域と周波数領域の統計情報を表示する。
SoX 処理チェインの中では、音声は変更を加えられずに通過する。
情報は'標準エラー'(stderr)ストリームに出力される。
情報の各項目についての説明を下の表にまとめる。
表の中の
n はサンプル数単位による音声の長さ,
c はチャンネル数,
r はサンプルレート,
xk は連続する各サンプルの(既定では -1 ~ +1 の範囲の) PCM 値
を表す:
PCM値:Pulse Code Modulation:パルス符号変調
Samples read
n×c
(読み取られたサンプル数)
Length (seconds)
n÷r
(長さ(秒))
Scaled by
下の -s を見よ。
Maximum amplitude
max(xk)
音声内のサンプルの最高値。 通常は正の値になる。
Minimum amplitude
min(xk)
音声内のサンプルの最低値。 通常は負の値になる。
Midline amplitude
1/2 min(xk) + 1/2 max(xk)
最高値+最低値の1/2、ほぼ0になるはず
Mean norm
1/n Σ|xk|
(平均ノルム)音声内の各サンプルの絶対値の平均
Mean amplitude
1/n Σxk
加算平均振幅。
音声の各サンプルの平均。 (正負あり)非ゼロを示す場合、 DC オフセットの存在を意味する(これは dcshift エフェクトを用いて除去できる)。
RMS amplitude
√(1/n Σxk^2)
二乗平均平方根振幅。音声の平均パワーと同じパワーのD.C. 信号レベル。(必ず正値) RMS:二乗平均平方根
Maximum delta
max(|xk - xk-1|)
(最大変位)サンプル間の差の最大値
Minimum delta
min(|xk - xk-1|)
(最小変位)サンプル間の差の最小値(たぶん0付近)
Mean delta
1/(n-1) Σ|xk - xk-1|
(平均変位)(正負あり)
RMS delta
√(1/(n-1) Σ(xk - xk-1)^2
( RMS 変位)(必ず正値)
Rough frequency
大まかな周波数。Hz 単位。
Volume Adjustment
(音量調整値) vol エフェクトに与えることができる、クリッピングを避けつつ,可能な限り音量を大きくするようなパラメータ。
注記:ほとんどの場合,実際にはこれを行うべきでないことの理由については、上述の クリッピング の説明を見よ。
出力例
Samples read: 16075776
Length (seconds): 182.265034
Scaled by: 2147483647.0
Maximum amplitude: 0.522400
Minimum amplitude: -0.511658
Midline amplitude: 0.005371
Mean norm: 0.001858
Mean amplitude: -0.000016
RMS amplitude: 0.011971
Maximum delta: 0.558472
Minimum delta: 0.000000
Mean delta: 0.000051
RMS delta: 0.000731
Rough frequency: 428
Volume adjustment: 1.914
SoX, SoXI, soxformat マニュアルページ日本語訳
のページがなくなっていたので、
自分がコピペしておいた stat の部分だけ貼っておく。
自分でメモを追加した部分もあり。
stat [-s scale] [-rms] [-freq] [-v] [-d]
ex)
sox.exe test.wav stat
標準エラーに出力されるので、こんな感じで使うのがよいか
sox.exe test.wav --null stat 2>&1
注:サンプル間の差分の情報は、多チャンネルには対応していない。
-s オプションは与えられた値で入力データをスケールする。
スケールのデフォルト値は 2147483647 (つまり32ビット符号付き整数の最大値)。
内部的には常に符号付きlong PCM データとされる。
そして値は与えられた値に関連している。
-rms オプションは、出力するすべての平均値を、(普通の加算平均でなく)二乗平均平方根に変換する。
-v オプションは 'Volume Adjustment' だけ出力する。
-freq オプションは、統計情報の代わりに、入力のパワースペクトラム(デフォルト4096個ずつ)を計算する。
モノラルチャンネルの音声ファイルのみに使える。
-d オプションは、soxの内部バッファで、32ビット符号付きPCMデータ音声を16進でダンプしたものを表示する。
これは主に、soxの異なるプラットフォームバージョン間で発生するエンディアン問題を見つけ出すのに役立つ。
音声の時間領域と周波数領域の統計情報を表示する。
SoX 処理チェインの中では、音声は変更を加えられずに通過する。
情報は'標準エラー'(stderr)ストリームに出力される。
情報の各項目についての説明を下の表にまとめる。
表の中の
n はサンプル数単位による音声の長さ,
c はチャンネル数,
r はサンプルレート,
xk は連続する各サンプルの(既定では -1 ~ +1 の範囲の) PCM 値
を表す:
PCM値:Pulse Code Modulation:パルス符号変調
Samples read
n×c
(読み取られたサンプル数)
Length (seconds)
n÷r
(長さ(秒))
Scaled by
下の -s を見よ。
Maximum amplitude
max(xk)
音声内のサンプルの最高値。 通常は正の値になる。
Minimum amplitude
min(xk)
音声内のサンプルの最低値。 通常は負の値になる。
Midline amplitude
1/2 min(xk) + 1/2 max(xk)
最高値+最低値の1/2、ほぼ0になるはず
Mean norm
1/n Σ|xk|
(平均ノルム)音声内の各サンプルの絶対値の平均
Mean amplitude
1/n Σxk
加算平均振幅。
音声の各サンプルの平均。 (正負あり)非ゼロを示す場合、 DC オフセットの存在を意味する(これは dcshift エフェクトを用いて除去できる)。
RMS amplitude
√(1/n Σxk^2)
二乗平均平方根振幅。音声の平均パワーと同じパワーのD.C. 信号レベル。(必ず正値) RMS:二乗平均平方根
Maximum delta
max(|xk - xk-1|)
(最大変位)サンプル間の差の最大値
Minimum delta
min(|xk - xk-1|)
(最小変位)サンプル間の差の最小値(たぶん0付近)
Mean delta
1/(n-1) Σ|xk - xk-1|
(平均変位)(正負あり)
RMS delta
√(1/(n-1) Σ(xk - xk-1)^2
( RMS 変位)(必ず正値)
Rough frequency
大まかな周波数。Hz 単位。
Volume Adjustment
(音量調整値) vol エフェクトに与えることができる、クリッピングを避けつつ,可能な限り音量を大きくするようなパラメータ。
注記:ほとんどの場合,実際にはこれを行うべきでないことの理由については、上述の クリッピング の説明を見よ。
出力例
Samples read: 16075776
Length (seconds): 182.265034
Scaled by: 2147483647.0
Maximum amplitude: 0.522400
Minimum amplitude: -0.511658
Midline amplitude: 0.005371
Mean norm: 0.001858
Mean amplitude: -0.000016
RMS amplitude: 0.011971
Maximum delta: 0.558472
Minimum delta: 0.000000
Mean delta: 0.000051
RMS delta: 0.000731
Rough frequency: 428
Volume adjustment: 1.914
↧
[R]最大エントロピー法による音声スペクトル解析
FFTではなくて、最大エントロピー法で周波数スペクトラムを得たかった。
ところが、最大エントロピー法とか、周波数解析とか
そのあたりの単語を一緒に検索しても
あんまりピンと来るような結果が出てこない。
理屈はどうでもいいから、R のソースが欲しいんだよ!
というわけで、自分で書いてみる。
書いてみると大したことないんだけど、
キーワードで引っかかるページを作りたかったの。
キーワード:
ARモデル 自己相関 Burg法
最大エントロピー法 MEM ( Maximum Entropy Methods )
library("tuneR")
FREQ <- 44100 # サンプリング周波数Hz
MYBY <- 10 # 何Hzごとに解析するか
fn <- "browniannoise.wav" # 対象のwavファイル
# waveファイルを読み込み
# from=0 を入れないと、最初の1秒は無視されちゃう
# 左チャンネルだけ使う(どっちでもいいけど)
wave.raw <- readWave(fn, from=0, units=c("seconds"))@left
# 時系列データに変換
tsdata <- ts(wave.raw, frequency=FREQ)
#Burg法に従って自己相関関数MEMスペクトルを得る
# n.freq プロットされる点の数
# order 当てはめられる AR モデルの次数
# 省略されると次数は AIC で選ばれる
# method 多分 "yule-walker" または "burg"
result <- spec.ar(tsdata, n.freq=(FREQ/MYBY/2)+1, plot=F, method="burg")
# プロットされる点は、最大で、サンプリング周波数の半分の周波数になるので、
# 最大 4410/2=>22050 個であるになる
# (サンプリング周波数の半分以上の周波数は、解析できない)
# ※n.freqを+1すると、result$freqにキレイな数が入る(0..2205なので0の分を足す)
# result$freq[0]は0が入るので、+1しといたほうがいいんじゃないか(根拠なし)
# 返り値
# specクラスオブジェクト
# result$freq 周波数のリスト
# result$spec 周波数に対応する値のリスト
plot(result) # グラフを表示
※参考
R 基本統計関数マニュアル
https://cran.r-project.org/doc/contrib/manuals-jp/Mase-Rstatman.pdf
orderを省略してみたが、
次数を赤池法でよしなに選んでもらっても
全然遅くない。
すごいな。
ユールウォーカー法でもいいんだけど、
みんながバーグ法のほうが良いって書いてるから、
バーグ法にしてみた。
全然わかっていないのだけど、
result$spec に入っている値って何なんだろう?
FFT みたいにパワー値が出てきているでもないのかしらん?
値の範囲がわからない。
上のサンプルの入力はブラウンノイズを使っているんだけど、
result$spec[1] には 870870.1 なんつー値が入っていた。
ビット深度 16bit で録音しているのだけど、
そのあたりをごにょごにょして、
なんか計算すれば、きっとなんかわかるんだろうな。
まぁいいや(良くない)
ところが、最大エントロピー法とか、周波数解析とか
そのあたりの単語を一緒に検索しても
あんまりピンと来るような結果が出てこない。
理屈はどうでもいいから、R のソースが欲しいんだよ!
というわけで、自分で書いてみる。
書いてみると大したことないんだけど、
キーワードで引っかかるページを作りたかったの。
キーワード:
ARモデル 自己相関 Burg法
最大エントロピー法 MEM ( Maximum Entropy Methods )
library("tuneR")
FREQ <- 44100 # サンプリング周波数Hz
MYBY <- 10 # 何Hzごとに解析するか
fn <- "browniannoise.wav" # 対象のwavファイル
# waveファイルを読み込み
# from=0 を入れないと、最初の1秒は無視されちゃう
# 左チャンネルだけ使う(どっちでもいいけど)
wave.raw <- readWave(fn, from=0, units=c("seconds"))@left
# 時系列データに変換
tsdata <- ts(wave.raw, frequency=FREQ)
#Burg法に従って自己相関関数MEMスペクトルを得る
# n.freq プロットされる点の数
# order 当てはめられる AR モデルの次数
# 省略されると次数は AIC で選ばれる
# method 多分 "yule-walker" または "burg"
result <- spec.ar(tsdata, n.freq=(FREQ/MYBY/2)+1, plot=F, method="burg")
# プロットされる点は、最大で、サンプリング周波数の半分の周波数になるので、
# 最大 4410/2=>22050 個であるになる
# (サンプリング周波数の半分以上の周波数は、解析できない)
# ※n.freqを+1すると、result$freqにキレイな数が入る(0..2205なので0の分を足す)
# result$freq[0]は0が入るので、+1しといたほうがいいんじゃないか(根拠なし)
# 返り値
# specクラスオブジェクト
# result$freq 周波数のリスト
# result$spec 周波数に対応する値のリスト
plot(result) # グラフを表示
※参考
R 基本統計関数マニュアル
https://cran.r-project.org/doc/contrib/manuals-jp/Mase-Rstatman.pdf
orderを省略してみたが、
次数を赤池法でよしなに選んでもらっても
全然遅くない。
すごいな。
ユールウォーカー法でもいいんだけど、
みんながバーグ法のほうが良いって書いてるから、
バーグ法にしてみた。
全然わかっていないのだけど、
result$spec に入っている値って何なんだろう?
FFT みたいにパワー値が出てきているでもないのかしらん?
値の範囲がわからない。
上のサンプルの入力はブラウンノイズを使っているんだけど、
result$spec[1] には 870870.1 なんつー値が入っていた。
ビット深度 16bit で録音しているのだけど、
そのあたりをごにょごにょして、
なんか計算すれば、きっとなんかわかるんだろうな。
まぁいいや(良くない)
↧
[win7]assemblyIdentity の processorArchitecture の値 x64 が無効
assemblyIdentity の processorArchitecture の値 x64 が無効です、
というエラーが、イベントログに残っている。
時刻は不定で、ほぼ毎日。
ログの名前: Application
ソース: SideBySide
日付: 2015/06/08 12:24:11
イベント ID: 63
タスクのカテゴリ: なし
レベル: エラー
キーワード: クラシック
ユーザー: N/A
コンピューター: alpaca
説明:
"C:\Program Files\r-3.2.0\Tcl\bin64\tk85.dll" のアクティブ化コンテキストの生成に失敗しました。マニフェストまたはポリシー ファイル "C:\Program Files\r-3.2.0\Tcl\bin64\tk85.dll" 行 9 のエラーです。 要素 "assemblyIdentity" の属性 "processorArchitecture" に無効な値 "x64" が指定されています。
あちこち調べてみたが、あまり情報がない。
違うな、情報はあるが、解決策がない。
調べていて、以下のページに当たった。
<runtime> の <assemblyIdentity> 要素 - MSDN
https://msdn.microsoft.com/ja-jp/library/b0yt6ck0(v=vs.110).aspx
processorArchitecture
省略可能な属性。
"x86"、"amd64"、"msil"、または "ia64" のいずれかの値で、プロセッサ固有のコードを含むアセンブリのプロセッサ アーキテクチャを指定します。 値の大文字と小文字は区別されません。 この属性にこれ以外の値を割り当てると、<assemblyIdentity> 要素全体が無視されます。 「ProcessorArchitecture」を参照してください。
えええええ。
省略できるならエラー出さないでよー。
エラーレベルは INFO とか WARN とかくらいでいいのにー。
x64 という値が設定不可なので、怒られているということはわかった。
じゃ、設定すべき値に書き換えましょう。
というわけで、リソースエディタで書き換えた!
※良い子はあまり真似しないように。
プログラムが起動しなくなる危険があるので、
ちゃんとバックアップを取ってから、自己責任で!
※ちなみに、使っているリソースエディタは
ResourceHacker とか ResEdit とか XNResouceEditor とか、
そのあたりを色々です。
今のところ、これでエラーは止まっている気がするので、
しばらく様子を見ることにする。
というエラーが、イベントログに残っている。
時刻は不定で、ほぼ毎日。
ログの名前: Application
ソース: SideBySide
日付: 2015/06/08 12:24:11
イベント ID: 63
タスクのカテゴリ: なし
レベル: エラー
キーワード: クラシック
ユーザー: N/A
コンピューター: alpaca
説明:
"C:\Program Files\r-3.2.0\Tcl\bin64\tk85.dll" のアクティブ化コンテキストの生成に失敗しました。マニフェストまたはポリシー ファイル "C:\Program Files\r-3.2.0\Tcl\bin64\tk85.dll" 行 9 のエラーです。 要素 "assemblyIdentity" の属性 "processorArchitecture" に無効な値 "x64" が指定されています。
あちこち調べてみたが、あまり情報がない。
違うな、情報はあるが、解決策がない。
調べていて、以下のページに当たった。
<runtime> の <assemblyIdentity> 要素 - MSDN
https://msdn.microsoft.com/ja-jp/library/b0yt6ck0(v=vs.110).aspx
processorArchitecture
省略可能な属性。
"x86"、"amd64"、"msil"、または "ia64" のいずれかの値で、プロセッサ固有のコードを含むアセンブリのプロセッサ アーキテクチャを指定します。 値の大文字と小文字は区別されません。 この属性にこれ以外の値を割り当てると、<assemblyIdentity> 要素全体が無視されます。 「ProcessorArchitecture」を参照してください。
えええええ。
省略できるならエラー出さないでよー。
エラーレベルは INFO とか WARN とかくらいでいいのにー。
x64 という値が設定不可なので、怒られているということはわかった。
じゃ、設定すべき値に書き換えましょう。
というわけで、リソースエディタで書き換えた!
※良い子はあまり真似しないように。
プログラムが起動しなくなる危険があるので、
ちゃんとバックアップを取ってから、自己責任で!
※ちなみに、使っているリソースエディタは
ResourceHacker とか ResEdit とか XNResouceEditor とか、
そのあたりを色々です。
今のところ、これでエラーは止まっている気がするので、
しばらく様子を見ることにする。
↧
[VMwarePlayer]VMwareToolsを手動で適用
VMwareTools の適用に失敗したので、手動での更新を試みる。
(実は毎回失敗してるんだけど、面倒くさくて、原因追及してない)
環境:
ホスト:windows7
ゲスト:Ubuntu Server 16
まず、一度失敗して、ログファイルの中からツールのURLを得る。
以下のログファイル中で、「http://」の部分を探す。
C:\Users\[username]\AppData\Local\Temp\vmware-[username]\vmware-vmplayer-****.log
411行目に以下を見つけたので、手動でダウンロード。
http://softwareupdate.vmware.com/cds/vmw-desktop/ws/14.1.1/7528167/windows/packages/tools-linux.tar
展開したら、以下が出てきた。
descriptor.xml
VMware-tools-linux-10.2.0-7259539.iso
VMwarePlayer のダウンロードディレクトリに置いた。
(どこに置いてもいいと思う)
実行中の VM で、
管理→仮想マシン設定→CD/DVD(SATA) で、
「ISOイメージファイルを使用する」を選んで、
上記の VMware-tools-linux-10.2.0-7259539.iso を選択。
CDマウント用ディレクトリにマウントする
方法は以下のページが詳しい
CentOS6.2にVMware Toolsをインストールする
適用方法もこのページに載っているので、書いてある通り写経すればOK。
(実は毎回失敗してるんだけど、面倒くさくて、原因追及してない)
環境:
ホスト:windows7
ゲスト:Ubuntu Server 16
まず、一度失敗して、ログファイルの中からツールのURLを得る。
以下のログファイル中で、「http://」の部分を探す。
C:\Users\[username]\AppData\Local\Temp\vmware-[username]\vmware-vmplayer-****.log
411行目に以下を見つけたので、手動でダウンロード。
http://softwareupdate.vmware.com/cds/vmw-desktop/ws/14.1.1/7528167/windows/packages/tools-linux.tar
展開したら、以下が出てきた。
descriptor.xml
VMware-tools-linux-10.2.0-7259539.iso
VMwarePlayer のダウンロードディレクトリに置いた。
(どこに置いてもいいと思う)
実行中の VM で、
管理→仮想マシン設定→CD/DVD(SATA) で、
「ISOイメージファイルを使用する」を選んで、
上記の VMware-tools-linux-10.2.0-7259539.iso を選択。
CDマウント用ディレクトリにマウントする
方法は以下のページが詳しい
CentOS6.2にVMware Toolsをインストールする
適用方法もこのページに載っているので、書いてある通り写経すればOK。
↧
↧